* Trash Web
- Webs
- BX12
- Book
- CC?
- Compare
- GPCE06
- GPCE08
- GPCE09
- GPCE10
- GPCE11
- GPCE12
- GPCE13
- GPCE14
- Gmt
- Gpce
- Gpce03
- Gpce04
- Gpce05
- Gpceorg
- HART14
- IFIPWG211
- IPA06
- Main
- Octave
- PEPM07
- PEPM08
- PEPM10
- PEPM11
- PEPM12
- PEPM13
- PEPM14
- PHP
- Sandbox
- Sdf
- SdfBackup
- Spoofax
- Stratego
- Sts
- TWiki
- Tiger
- Tools
- Transform
- Trash
- Variability
- WGLD
- WebDSL
- default?
Searched: \.*
Results from Trash web
Abstract: ZL is a C++-compatible language in which high-level constructs, such
as classes, are defined using macros over a C-like core language. This
approach makes many parts of the language easily customizable. For example,
since the class construct can be defined using macros, a programmer
can have complete control over the memory layout of objects. Using
this capability, a programmer can mitigate certain problems in
software evolution such as fragile ABIs (Application Binary
Interfaces) due to software changes and incompatible ABIs due to
compiler changes. In this paper, we outline the problem of fragile and
incompatible ABIs and show how ZL can be used to solve them.
AComponentbasedRuntimeEvolutionInfrastructureForResourceConstrainedEmbeddedSystems (07 Aug 2012 - 17:09 - r1.2 - WalterBinder)
Abstract: This paper deals with embedded systems software and the modification of its architecture and behavior at execution-time. Incautious implementation of such capabilities demands heavy memory and performance overrun. To accomplish such software evolution activities in resource-constrained embedded systems, we propose
a component-based run-time evolution infrastructure that reconciles richness of evolution alternatives and performance requirements. Our proposition is based on off-site components reifications, representations of components which allow us to treat evolution concerns remotely and hence to alleviate the workload to be processed by the embedded device. Memory and processor-time resources consumption evaluation on a real-world scenario show the efficiency and pertinence of our approach.
Abstract: Delta modeling is an approach to facilitate automated product derivation for software product lines. It is based on a set of deltas specifying modifications that are incrementally applied to a core product. The applicability of deltas depends on feature-dependent conditions. This paper presents abstract delta modeling, which explores delta modeling from an abstract, algebraic perspective. Compared to previous work, we take a more flexible approach with respect to conflicts between modifications and introduce the notion of conflict resolving deltas. We present conditions on the structure of deltas to ensure unambiguous product generation.
Abstract: Plug-in components are a means for making feature-rich applications customizable. Combined with plug-and-play composition, end users can assemble customized applications without programming. If plug-and-play composition is also dynamic, applications can be reconfigured on the fly to load only components the user needs for his current work. We have created Plux.NET, a plug-in framework that supports dynamic plug-and-play composition. The basis for plug-and-play in Plux is the composer which replaces programmatic composition by automatic composition. Components just specify their requirements and provisions using metadata. The composer then assembles the components based on that metadata by matching requirements and provisions. When the composer needs to reuse general-purpose components in different parts of an application, the component model requires genericity. The composer depends on metadata that specify which components should be connected and for general-purpose components those metadata need to be different on each reuse. We present an approach for generic plug-ins with component templates and an implementation for Plux. The general-purpose components become templates and the templates get parameterized when they are composed.
- Name: andrea scavuzzo
- Email: andrea.scavuzzo@tin.it
- Homepage URL: http://twiki.org
- Country: Italy
- WelcomeGuest to learn TWiki
- Sandbox web to try out TWiki
- AndreaScavuzzoSandbox? just for me
- Show tool-tip topic info on mouse-over of WikiWord links, on or off: (see details in TWikiPreferences)
- Set LINKTOOLTIPINFO = off
- Horizontal size of text edit box:
- Set EDITBOXWIDTH = 70
- Vertical size of text edit box:
- Set EDITBOXHEIGHT = 22
- Style of text edit box.
width: 99%for full window width (default),width: autoto disable.- Set EDITBOXSTYLE = width: 99%
- Optionally write protect your home page: (set it to your WikiName)
- Set ALLOWTOPICCHANGE =
- ChangePassword?
- TWikiPreferences has site-level preferences of TWiki.
- WebPreferences has preferences of the TWiki.Trash web.
- TWikiUsers has a list of other TWiki users.
ApplicationsOfDynamicCodeEvolutionForJavaInGUIDevelopmentAndDynamicAspectOrientedProgramming (07 Aug 2012 - 19:28 - r1.2 - WalterBinder)
Abstract: While dynamic code evolution in object-oriented systems is an important feature supported by dynamic languages, there is currently only limited support for dynamic code evolution in high-performance, state-of-the-art runtime systems for statically typed languages, such as the Java Virtual Machine.
In this tool demonstration, we present the Dynamic Code Evolution VM, which is based on a recent version of
Oracle's state-of-the-art Java HotSpot(TM) VM and allows unlimited changes to loaded classes at runtime. Based on the Dynamic Code Evolution VM, we developed an enhanced version of the Mantisse GUI builder (which is part of the NetBeans IDE) that allows adding GUI components without restarting the application under development. Furthermore, we redesigned the dynamic AOP framework HotWave to take advantage of the enhanced dynamic code evolution capabilities. The new version, HotWave2, now supports most AspectJ constructs, including "around()" advice and static cross-cutting. We will demonstrate both the enhanced Mantisse GUI builder as well as HotWave2, weaving several aspects for dynamic analysis in sizable applications at runtime.
Abstract: Operation contracts consisting of pre- and postconditions are a well-known means of specifying operations. In this paper we deal with the problem of operation contract simulation, i.e. determining operation results satisfying the postconditions based on input data supplied by the user; simulating operation contracts is an important technique for requirements validation and prototyping. Current approaches to operation contract simulation exhibit poor performance for large sets of input data or require additional guidance from the user. We show how these problems can be alleviated and describe an efficient as well as fully automatic approach. It is implemented in our tool OCLexec that generates from UML/OCL operation contracts corresponding Java implementations which call a constraint solver at runtime. The generated code can serve as a prototype. A case study demonstrates that our approach can handle problem instances of considerable size.
AutomaticVariationPointIdentificationInFunctionBlockBasedModels (07 Aug 2012 - 19:28 - r1.2 - WalterBinder)
Abstract: Function-block-based modeling is often used to develop embedded systems, particularly as system variants can be developed rapidly from existing modules. Generative approaches can simplify the handling and development of the resulting high variety of function-block-based models. But they often require the development of new generic models that do not utilize existing ones. Reusing existing models will significantly decrease the effort to apply generative programming. This work introduces an automatic approach to recognize variants in a set of models and identify the variation points and their dependencies within the variants. As result it offers automatically generated feature models and ICCL content to generate the given variants.
Spoofax is a platform for developing textual domain-specific languages with full-featured Eclipse editor plugins.
With the Spoofax/IMP language workbench, you can write the grammar of your language using the high-level SDF grammar formalism. Based on this grammar, basic editor services such as syntax highlighting and code folding are automatically provided. Using high-level descriptor languages, these services can be customized. More sophisticated services such as error marking and content completion can be specified using rewrite rules in the Stratego language.
(more features)
Spoofax Features
| Edit and use your language in one Eclipse window |
|
| Deploy your editor as a portable Eclipse plugin |
|
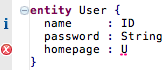
| Specify custom errors, warnings, and notes |
|
| Support content completion |

|
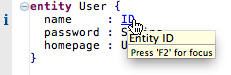
| Support reference resolving |
|
| Use concise rewrite rules for code generation |

|
| Generate code directly from any editor or selection |
|
| Apply refactoring transformations on the source code |
|
| Get a live abstract syntax view |
|
Abstract: Some limitations of object-oriented mechanisms are known to cause code
clones (e.g., extension using inheritance). Novel programming paradigms
such as feature-oriented programming (FOP) aim at alleviating these
limitations. However, it is an open issue whether FOP is really able to
avoid code clones or whether it even facilitates (FOP-specific) clones.
To address this issue, we conduct an empirical analysis on ten
feature-oriented software product lines with respect to code cloning. We
found that there is a considerable amount of clones in feature-oriented
software product lines and that a large fraction of these clones is
FOP-specific (i.e., caused by limitations of feature-oriented
mechanisms). Based on our results, we initiate a discussion on the
reasons for FOP-specific clones and on how to cope with them.
Abstract: Aspect-oriented programming provides a convenient high-level model to define several kinds of dynamic analyses, in particular thanks to recent advances in exhaustive weaving in core libraries. Casting dynamic analyses as aspects allows the use of a single weaving infrastructure to apply different analyses to the same base program, simultaneously. However, even if dynamic analysis aspects are mutually independent, their mere presence perturbates the observations of others: this is due to the fact that aspectual computation is potentially visible to all aspects. Because current aspect composition approaches do not address this kind of computational interference, combining different analysis aspects yields at best unpredictable results. It is also impossible to flexibly combine various analyses, for instance to analyze an analysis aspect. In this paper we show how the notion of execution levels makes it possible to effectively address these composition issues. In order to realize this approach, we explore the practical and efficient integration of execution levels in a mainstream aspect language, AspectJ. We report on a case study of composing two out-of-the-box analysis aspects in a variety of ways, highlighting the benefits of the approach.
On the first day, you need to install Eclipse and the Spoofax language workbench.
Installation
We highly recommend to work with a fresh Eclipse installation. You may also install some additional Eclipse plug-ins to which you are used to, e.g. for version management. Moved to http://metaborg.org/wiki/spoofax/downloadInitial Project
We recommend to start with an empty Eclipse workspace. Import the initial project? using the Import > General/Existing Projects into Workspace wizard. Build the project by selecting it and choosing Project > Build Project from the menu. The console will report success or failure.On the third day, you define the concrete and abstract syntax for the MiniJava language.
While you extend your syntax definition step by step, it is very handy to have multiple start symbols.
But in the end, 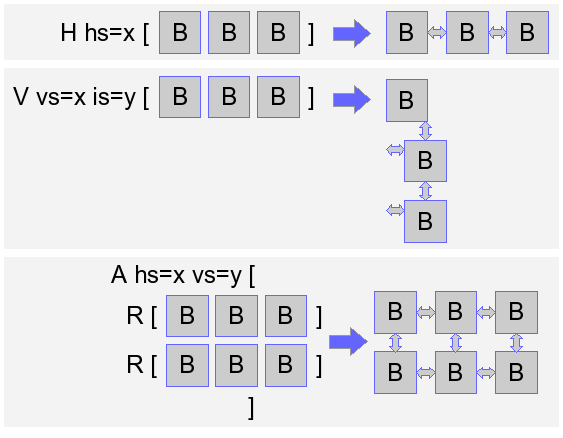 The exact formatting of each Box operator can be customized using Box options. For example, to control the horizontal layout between boxes the
The exact formatting of each Box operator can be customized using Box options. For example, to control the horizontal layout between boxes the
To be able to specify formattings for all nested constructs that are allowed in SDF productions, so called selectors are used in pretty-print tables to refer to specific parts of an SDF production and to define a formatting for them. For example, the SDF prodcution
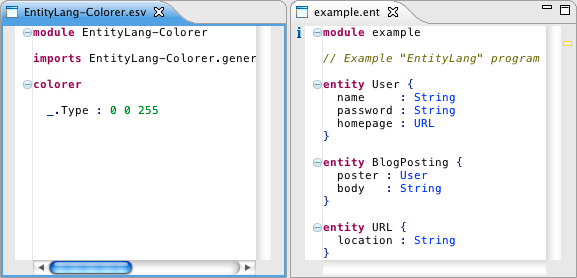 It specifies a color for keywords (alphanumeric literals in the grammar), operators (non-alphanumeric literals), strings (lexical sorts that allow spaces), numbers (lexical numeric sorts), and identifiers (other lexical sorts). The default highlighting works well, but can be customized in the
It specifies a color for keywords (alphanumeric literals in the grammar), operators (non-alphanumeric literals), strings (lexical sorts that allow spaces), numbers (lexical numeric sorts), and identifiers (other lexical sorts). The default highlighting works well, but can be customized in the
 Spoofax uses heuristics to automatically derive a generated folding descriptor, based on the logical nesting structure in the syntax of the language.
Currently, productions rules that have a lexical identifier and child elements are included in this descriptor. While not perfect, the heuristic provides a good starting point for a new folding definition. Any undesired definitions in the generated file can be disabled by using the
Spoofax uses heuristics to automatically derive a generated folding descriptor, based on the logical nesting structure in the syntax of the language.
Currently, productions rules that have a lexical identifier and child elements are included in this descriptor. While not perfect, the heuristic provides a good starting point for a new folding definition. Any undesired definitions in the generated file can be disabled by using the
-- GuidoWachsmuth - 03 Oct 2012
Syntax Definition
You should build the syntax definition step by step. As a syntax definition formalism, you can choose either SDF or the Template Language.Lexical Syntax
Start with the lexical syntax definition including identifiers, integer, and simple layout. First, define lexical syntax rules. Second, define follow restrictions to ensure longest matches. Finally, use rejection rules to rule out reserved words in Java.
INT and ID. For grading, it is required to comply with these sort names literally.
|
Context-free Syntax
Continue with the context-free syntax of the language. Use the context-free grammar from the book as a reference. First, define context-free syntax rules. Next, add constructors for abstract syntax trees to your rules. Complete the definition with appropriate disambiguation rules.
Program, MainClass, ClassDecl, VarDecl, MethodDecl, Type, Statement and Exp. For grading, it is required to comply with these sort names literally.
|
Comments
Finally, you should add lexical syntax rules for comments to your syntax definition. Start with simple line comments. Continue with simple block comments and extend them to support nested comments. Do not forget to define follow restrictions.Testing the Syntax Definition
After each step, you can check your progress by building the project and running your test cases. Therefor, you need to declare the same start symbols in your syntax definition as in your test suites. To also test your MiniJava editor interactively, you need to specify the start symbols also in the main editor descriptioneditor/MiniJava.main.esv.
You can also use Show AST in the editor's Transform menu to test your abstract syntax definition interactively.
Program should be the only start symbol.
This will break many of your test suites.
You can fix this by removing start symbol declarations in these test suites.
Instead, you need to specify a setup header and footer to embed your test cases into a complete MiniJava program.
module example language MiniJava setup MiniJava program header [[...]] test ... test ... setup MiniJava program footer [[...]]Box is a mark-up language to describe the intended layout of text and is used in pretty print tables. A Box expression is constructed by composing sub-boxes using Box operators. These operators specify the relative ordering of boxes. Examples of Box operators are the
H and V operator which format boxes horizontally and vertically, respectively.
The exact formatting of each Box operator can be customized using Box options. For example, to control the horizontal layout between boxes the H operator supports the hs space option.
|
|
Anatomy of a Pretty Print Table
Pretty-print tables are used to specify how language constructs have to be pretty-printed. They use Box as language to specify formatting of language constructs. Spoofax generates a pretty-print table from your syntax definition. You can find it insyntax/MiniJava.generated.pp.
It contains mappings from constructor names to Box expressions. For example, for the SDF production
Exp "+" Exp -> Exp {cons("Plus")}
A pretty-print entry looks like:
Plus -- H hs=1 [ _1 "+" _2]
|
|
Exp "." ID "(" {Exp ","}* ")" -> Exp {cons("Call")}
contains a nested symbol {Exp ","}*. To specify a formatting for this production, two pretty-print entries can be used:
Call -- _1 KW["."] _2 KW["("] _3 KW[")"],
Call.3:iter-star-sep -- _1 KW[","],
A selector consists of a constructor name followed by a list of number and type tuples. A number selects a particular subtree of a constructor application, the type denotes the type of the selected construct (sequence, optional, separated list etc.). Specifying both the number of a subtree and its type allows unambiguous selection of subtrees and makes pretty-print tables easier to understand.
Below we summarize which selector types are available:
-
opt - For SDF optionals
S?. -
iter - For non-empty SDF lists
S+. -
iter-star - For possible empty SDF lists
S*. -
iter-sep - For SDF separator lists
{S1 S2}+. Observe that the symbolS1and the separatorS2are ordinary subtrees of theiter-sepconstruct which can be referred to as first and second subtree, respectively. -
iter-star-sep - For SDF separator lists
{S1 S2}*. Its symbolS1and separatorS2can be refered to as first and second subtree. -
alt - For SDF alternatives
S1 | S2 | S3. According to the SDF syntax, alternatives are binary operators. The pretty-printer flattens all subsequent alternatives. Pretty-print rules can be specified for each alternative individually by specifying the number of each alternative. -
seq - For SDF groupings
(S1 S2 S3).
Customising Pretty Print Tables
Generated pretty-print tables can easiliy be customised by overruling them in additional pretty-print tables. You can define your own pretty-print table insyntax/MiniJava.pp, which is initially empty.
Here you should add your own rules to improve parts of the generated table.
|
|
Editor Integration
To test your pretty-printer, you need to define a builder and a corresponding strategy. Here you make your first contact to Stratego, Spoofax' language for term rewriting. Add the following rewrite rule totrans/minijava.str:
pretty-print:
(selected, position, ast, path, project-path) -> (filename, text)
where
filename := <guarantee-extension(|"pp.mjv")> path ;
text := <pp-minijava-string> selected
This rule follows Spoofax' convention for strategies which implement editor services. On the left-hand site, it matches a tuple of the selected node, its position in the ast, the path of the current file and the project path. On the right-hand site, it instantiates a pair, consisting of a filename and the designated text of the file.
Both variables are bound in the where clause. The file name is derived from the path of the current file, while the content of the file is a pretty-printed version of the selected AST node. Therefor, a strategy pp-minijava-string is applied to the node. You can see its definition, which is generated by Spoofax, in lib/editor-common.generated.str:
pp-minijavasummer-string =
<ast2abox(|[<import-term(include/MiniJava.generated.pp.af)>, <import-term(include/MiniJava.pp.af)>])> selected => box ;
<box2text-string(|100)> box => text
This strategy imports both pretty-printing tables, applies them to turn the AST node into boxes, and then turns these boxes into a string with a maximum line width of 100 characters.
Now we can hook our strategy into the editor, making pretty-printing available in the Transform menu.
Add the following builder definition to editor/MiniJava-Builders.esv:
builder : "Pretty-print syntax" = pretty-print (openeditor) (realtime) (meta) (source)This rule defines a
builder, its label in the Transform menu, and its implementation strategy pretty-print.
Annotations can be used for different variants of builders. (openeditor) ensures that a new editor window is opened for the result. (realtime) requires this editor to be updated whenever the content in the original editor changes. (meta) restricts the builder to be only available to the language engineer, but not to the language user. While you can invoke the builder, people who install your MiniJava plugin cannot. Finally, (source) tells Spoofax to run the builder on an unanalysed (and also not desugared) AST.
|
|
Presentational editor services
Presentational editor services such as syntax highlighting, code folding, and the outline view are defined inesv files in the editor directory.
You need to specify editor services for your MiniJava editor in the following files:
* syntax highlighting: editor/MiniJava-Colorer.esv,
* outline view: editor/MiniJava-Outliner.esv,
* code folding: editor/MiniJava-Folding.esv,
* code templates: editor/MiniJava-Completion.esv.
These files import files which were generated from your grammar.
|
|
Syntax Highlighting
Default syntax highlighting behaviour is derived based on the literals and lexical syntax in the grammar. The colours used for this derived behavior are specified in the generatedMiniJava-Colorer.generated.esv descriptor:
It specifies a color for keywords (alphanumeric literals in the grammar), operators (non-alphanumeric literals), strings (lexical sorts that allow spaces), numbers (lexical numeric sorts), and identifiers (other lexical sorts). The default highlighting works well, but can be customized in the MiniJava-Colorer.esv file.
Custom colouring rules for the context-free elements need to specify the sort together with specific colours for some or all of its constructors.
Other colouring rules can override the colors for literals and lexical sorts, and can specify background colors, colors for regions of code rather than single productions, and more.
You can now try to come up with an own highlighting scheme for MiniJava.
|
|
Code Folding and Outline View
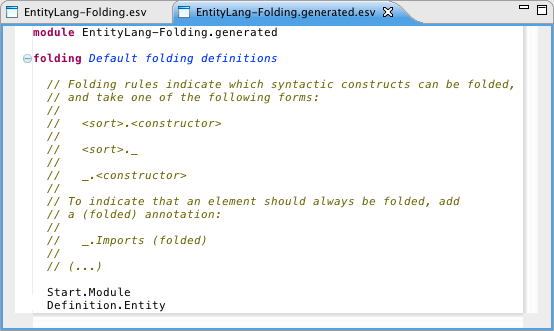
Code folding and the outline view are specified by selecting grammar productions that should be made foldable or shown in the outline view. The following picture illustrates some folding rules for another Spoofax project:
Spoofax uses heuristics to automatically derive a generated folding descriptor, based on the logical nesting structure in the syntax of the language.
Currently, productions rules that have a lexical identifier and child elements are included in this descriptor. While not perfect, the heuristic provides a good starting point for a new folding definition. Any undesired definitions in the generated file can be disabled by using the (disabled) annotation in the custom specification.
The (folded) annotation can be used for constructs that should be folded automatically.
You should enable content folding for class and method declarations as well as for if-, while- and block statements.
In the same way, you can then specify the outline outline view showing classes with their fields and methods, including parameters, variable declarations and types.
| %GS% Challenge: The grammar from the book inhibits a nice outline of the main class and the main method. Try to change your grammar in a way, that you can specify an outline for the main class and main method. Try to make it as similar as possible to the one for ordinary classes and methods. |
Code Completion Templates
Syntactic content completion provides users with completion suggestions based purely on static, syntactic templates. For example
completion template Statement:
"while (" <e> ") {\n\t" <b> "\n}"
is a syntactic completion rule for while loops. Such rules are composed of static strings and placeholder expressions. Static strings allow for precise control of the pre- sentation and are enclosed by double quotes. They can use \n for newlines or \t for one indentation level (following the users tab/space configuration). Placeholder expressions are indicated by angular brackets. The editor automatically moves the cursor to these expressions once the user selects a completion proposal, allowing the expressions to be filled in as the user continues typing.
Define your own completion rules for code completion on language constructs which you consider most useful.
| %GS% Challenge: Instead of specifying pretty-print tables and code completion rules separately, you might switch to the Template Language. In this language, you can define the syntax of a language, pretty-printing, and syntactic code completion in a single definition formalism. . |
On the fifth day, you should specify test cases for the static analysis of MiniJava programs.
Initial Project
You should start the second milestone from a new initial project. First, either close or delete your project for the first milestone. Second, import the initial project? using the Import > General/Existing Projects into Workspace wizard. Next, Build the project by selecting it and choosing Project > Build Project from the menu. The console will report success or failure. Finally, study the constructors used in ASTs. You can do this either by inspecting the AST of an example program or by inspecting the signature inassignment1/MiniJava.str.
Test Cases
Like in the first milestone, you should specify test cases before you start with the implementation. You need three types of test cases:- Tests for reference resolution. Define test cases for different kinds of references to declarations.
- Tests for error checking. Define test cases for checking errors which are related to names and types.
- Tests for transformations. Define test cases for the results of type projections.
Testing Reference Resolution
In test cases for reference resolution, you need to mark names at definition and use sites with inner square bracket blocks. You can then relate the use site with the definition site in aresolve ... to ... clause, using numbers to refer to the inner blocks.
For example, the following two test cases require to resolve the type Foo to the name in the definition of class Foo:
test forward class name resolution [[
class Main {
public static void main(String[] args) {
System.out.println(1);
}
}
class Foobar {
[[Foo]] x;
}
class [[Foo]] {}
]] resolve #1 to #2
test backward class name resolution [[
class Main {
public static void main(String[] args) {
System.out.println(1);
}
}
class [[Foo]] {}
class Foobar {
[[Foo]] x;
}
]] resolve #2 to #1
|
|
Testing Error Checking
In test cases for error checking, you need o specify the number of errors, warnings, or notes in a test case in... errors, ... warnings, or ... notes clauses.
You can use inner square bracket blocks to mark the positions where messages should be reported.
For example, the following test cases specify a correct MiniJava program, a program with two errors which are reported on the name of a duplicate class Foo, and another program with a warning which is reported on the name of an unused class Foobar:
test correct program [[
class Main {
public static void main(String[] args) {
System.out.println(1);
}
}
class Foo {}
class Foobar {
Foo x;
}
]] 0 errors
test error on duplicate class [[
class Main {
public static void main(String[] args) {
System.out.println(1);
}
}
class [[Foo]] {}
class [[Foo]] {}
]] 2 errors
test waring on unused class [[
class Main {
public static void main(String[] args) {
System.out.println(1);
}
}
class Foo {}
class [[Foobar]] {
Foo x;
}
]] 1 warning
|
|
Testing Transformations
Finally, you can test transformations by specifying the name of a strategy and the expected result in a withrun ... to... clause. Again, you can mark the relevant part in the program with inner square brackets. For example, the following test case checks the result of applying type-of to an expression:
test type of addition is integer [[
class Main {
public static void main(String[] args) {
System.out.println([[1+1]]);
}
}
]] run type-of to Int()
Required Test Cases
Name Analysis
You need to specify test cases for the resolution of- class names,
- field names,
- method calls,
- parameter names, and
- variable names.
- errors on duplicate definitions,
- errors on missing definitions,
- warnings on unused definitions,
- errors on cyclic inheritance,
- errors on hiding fields,
- warnings on hiding variables,
- errors on overloaded methods,
- notes on overriding methods, and
- errors on instantiating or subclassing the main class.
Type Analysis
You should specify test cases regarding thetype-of strategy for all kinds of expressions.
Additionally, you should have test cases for type-related errors in
- expressions,
- statements, and
- methods.
EfficientExtractionAndAnalysisOfPreprocessorBasedVariability (07 Aug 2012 - 19:29 - r1.2 - WalterBinder)
Abstract: The CPP is the dominant tool of choice for the implementation of variability in large-scale configurable software. Linux, probably the most-configurable piece of software ever, employs more than 10,000 preprocessor variables for this purpose. However, this de-facto variability tends to be ``hidden in the code''; which on the long term leads to varibility defects, such as dead code or inconsistencies with respect to the intended (modelled) variability of the software. This calls for tool support for the efficient extraction of (and reasoning over) CPP-based variability.
We suggest a novel approach to extract CPP-based variability. Our tool transforms CPP-based variability in O(n) complexity into a propositional formula that ``mimics'' all valid effects of conditional compilation and can be queried with standard SAT or BDD packages.
Our evaluation results demonstrate the scaleability and practicability of the approach. A dead-block-analysis on the complete Linux source tree takes less than 15 minutes; we thereby have revealed 4 defects, 2 of which meanwhile have been confirmed as new (and long-lasting) bugs.
Details about the GPCE'06 tutorials will follow later. The deadline for proposal submissions is March 18, 2006.
Workshops/Tutorials chairs:
- Christa Schwanninger (Siemens, Germany)
- Arno Jacobsen (University of Toronto, Canada)
Details about the GPCE'06 Workshops will follow later.
Abstract: Writing correct and efficient concurrent programs still
remains a challenge. Explicit concurrency is difficult,
error prone, and creates code which is hard to maintain
and debug. This type of concurrency also treats modular
program design and concurrency as separate goals, where
modularity often suffers.
To solve these problems, we are designing a new language
that we call Panini. In this paper, we focus on Panini's
asynchronous, typed events, which reconcile the modularity
goal promoted by the implicit invocation design style
with the concurrency goal of exposing potential concurrency
between the execution of subjects and observers.
Since modularity is improved and concurrency is implicit
in Panini, programs are easier to reason about and maintain.
Furthermore, races and deadlocks are avoided entirely,
yielding programs with a guaranteed sequential semantics.
To evaluate our language design and implementation we show
several examples of its usage as well as an empirical study
of program performance.
We found that not only is developing and understanding
Panini programs significantly easier compared to standard
concurrent object-oriented programs, but performance of
Panini programs is also comparable to their equivalent
hand-tuned versions written using Java's fork-join framework.
Abstract: Garcia introduces a calculus for type-reflective metaprogramming that provides much of the power and flexibility of C++ templates and solves many of its problems. However, one of the problems that remains is that the residual program is not type checked until after meta computation is complete. Ideally, one would like the type system of the metaprogram to also guarantee that the residual program will type check, as is the case in MetaML. However, in a language with type-reflective metaprogramming, type expressions in the residual program may be the result of meta computation, making the MetaML guarantee next to impossible to achieve.
In this paper we offer an approach to detecting errors earlier without sacrificing flexibility: we incrementally type check code fragments as they are created and spliced together during meta computation. The incremental type system is a variant of the gradual type system of Siek and Taha, in which we use type variables to represent type expressions that are not yet normalized and a new dynamic variation on existential types to represent residual code fragments. A type error in a code fragment is treated as a run-time error of the meta computation. We show that the incremental type checker can be implemented efficiently and we prove that if a well-typed metaprogram generates a residual program, then the residual program is also well-typed.
Abstract: Type inference is the process of constructing a typing derivation while gradually discovering type information.
During this process, inference algorithms typically make subtle decisions based on the derivation constructed so far.
Because a typing derivation is a decorated tree we aim to use attribute grammars as the main implementation tool. Unfortunately, we can neither express iteration, nor express decisions based on intermediate derivations in such grammars.
Here, we present the language |rulerfront|, a conservative extension to ordered attribute grammars, that deals with the aforementioned problems. We show why this extension is suitable for the description of constraint-based inference algorithms.
Abstract: Manually implementing equals (for object comparisons) and
hashCode (for object hashing) methods in large software
projects is tedious and error-prone. This is due to many special cases,
such as field shadowing, comparison between different types, or cyclic
object graphs. Here, we present JEqualityGen, a source code generator
that automatically derives implementations of these methods.
JEqualityGen proceeds in two states: it first uses source code
reflection in MetaAspectJ to generate aspects that contain the method
implementations, before it uses weaving on the bytecode level to insert
these into the target application. JEqualityGen generates not only
correct, but efficient source code that on a typical large-scale Java
application exhibits a performance improvement of more than two orders
of magnitude in the equality operations generated, compared to an
existing system based on runtime reflection. JEqualityGen achieves this
by generating runtime profiling code that collects data. This
enables it to generate optimised method
implementations in a second round.
- Name: Jerry Juarez
- Email: jzerauj@gmail.com
- Homepage URL: http://mage.celeriansys.com
- Country: USA
- WelcomeGuest to learn TWiki
- Sandbox web to try out TWiki
- JerryJuarezSandbox? just for me
- Show tool-tip topic info on mouse-over of WikiWord links, on or off: (see details in TWikiPreferences)
- Set LINKTOOLTIPINFO = off
- Horizontal size of text edit box:
- Set EDITBOXWIDTH = 70
- Vertical size of text edit box:
- Set EDITBOXHEIGHT = 22
- Style of text edit box.
width: 99%for full window width (default),width: autoto disable.- Set EDITBOXSTYLE = width: 99%
- Optionally write protect your home page: (set it to your WikiName)
- Set ALLOWTOPICCHANGE =
- ChangePassword?
- TWikiPreferences has site-level preferences of TWiki.
- WebPreferences has preferences of the TWiki.Trash web.
- TWikiUsers has a list of other TWiki users.
-- AndreeaCostea - 27 Jun 2013
LightweightModularStagingAPragmaticApproachToRuntimeCodeGenerationAndCompiledDSLs (07 Aug 2012 - 19:30 - r1.2 - WalterBinder)
Abstract: Software engineering demands generality and abstraction, performance demands specialization and concretization. Generative programming can provide both, but developing high-quality program generators takes a large effort, even if a multi-stage programming language is used.
We present lightweight modular staging, a library-based multi-stage programming approach that breaks with the tradition of syntactic quasi-quotation and instead uses only types to distinguish between binding times. Through extensive use of component technology, lightweight modular staging makes an optimizing compiler framework available at the library level, allowing programmers to tightly integrate domain-specific abstractions and optimizations into the generation process.
We argue that lightweight modular staging enables a form of language virtualization, i.e. allows to go from a pure-library embedded language to one that is practically equivalent to a stand-alone implementation with only modest effort.
Under Construction
A Language for Software Variation Research
Martin Erwig, Oregon State University, USA
Managing variation is an important problem in software engineering that takes different forms, ranging from version control and configuration management to software product lines. In this talk, I present our recent work on the choice calculus, a fundamental representation for software variation that can serve as a common language of discourse for variation research, filling a role similar to lambda calculus in programming language research. After motivating the design of the choice calculus and sketching its semantics, I will discuss several potential application areas. Abstract: Modular robots are mechatronic devices that enable the construction of highly versatile and flexible robotic systems that can dynamically modify their assembled mechanical structure. The key feature that enables this dynamic modification is the capability of the individual modules to connect to each other in multiple ways and thus generate a number of different mechanical systems, in contrast with the monolithic, fixed structure of conventional robots. The mechatronic flexibility, however, complicates the development of models and programming abstractions for modular robots, since manually describing and enumerating the full set of possible interconnections is tedious and error-prone for real-world robots. In order to allow for a general formulation of spatial abstractions for modular robots and to ensure correct and streamlined generation of code dependent on mechanical properties, we have developed the Mechatronics Description Language (MDL). MDL is a domain-specific language, which can model the kinematic structure of individual robot modules and declaratively describe their possible interconnections, rather than requiring the user to enumerate them in their entirety. From this description, the MDL compiler generates the code that is needed to simulate the resulting robots within Webots, a widely used commercial robot simulator, and the software component needed for spatial structure computations by a virtual machine-based runtime system, which we have developed and use for programming physical modular robots.
Abstract: Programs in domain-specific embedded languages (DSELs) can be represented in the host language in different ways, for instance implicitly as libraries, or explicitly in the form of abstract syntax trees. Each of these representations has its own strengths and weaknesses. The implicit approach has good composability properties, whereas the explicit approach allows more freedom in making syntactic program transformations.
Traditional designs for DSELs fix the form of representation, which means that it is not possible to choose the best representation for a particular interpretation or transformation. We propose a new design for implementing DSELs in Scala which makes it easy to use different program representations at the same time. It enables the DSL implementor to define modular language components and to compose transformations and interpretations for them.
Test page.
Invited Talk by Oege de Moor
Joint work with Elnar Hajiyev, and Mathieu Verbaere
Abstract
Code queries are useful for enforcing coding conventions, navigating a large code base, and for identifying locations to refactor. The program understanding community has long advocated the use of a relational database to facilitate such code queries, but relational queries over code have not found widespread use. We argue this is due to a lack of scalability (it takes too long to evaluate queries), and a lack of a modern query language with all the tool support that entails (writing code queries in SQL can take many pages). In this talk we demonstrate a new system that goes some way towards alleviating both problems. First, we demonstrate IQL, an object-oriented query language. It allows the concise expression of complex queries; due to its object-oriented features, it is easy to extend and modify existing queries. Another benefit of object-orientation is that it gives natural tool support, for instance for auto-completion. The semantics of IQL is defined by translation to Datalog. Datalog is a logic programming language like Prolog, but it lacks data structures. As a consequence, all queries in Datalog are guaranteed to terminate, and they have a very simple semantics, enabling aggressive optimisations. While Datalog has been extensively studied in the theoretical database community, it lacks a proper type system. We introduce a type system with subtyping to account for the class hierarchy of IQL. Type inference is achieved via an abstract interpretation that maps each relation between runtime values to a relation between binding sites. We implement Datalog itself via a compiler to procedural SQL; a configuration file allows us one target different relational database systems as the backend. The compiler performs many optimisations, ranging from straightforward constant propagation to a form of the well-known `magic sets' transformation. It also performs type specialisation, based on the abstract interpretation in the type inference algorithm.Since SDF is starting to be used structurally in the Stratego
compiler, the LEX/YACC definition is no longer part of the distribution (starting with StrategoRelease09 beta7). It
is a pain to maintain and to keep the two definitions in synch.
-- EelcoVisser - 13 Dec 2002
Content
-- FrankHermann - 29 Mar 2012
Aspect-oriented programming languages support the modular definition of crosscutting abstractions. In most languages, this is achieved through pointcuts, which provide a means for quantifying over execution events in order to implicitly trigger advice. Notably, an advice is more than a simple event handler because of its ability to override the underlying computation. Unrestricted quantification and arbitrary advice computation are powerful but dangerous.
In this talk we look at a number of approaches to tame aspects in order to retain their benefits without sacrificing important software engineering properties, like modular reasoning, separate development, type soundness, and controlled interferences. Specifically, we report on advances in scoping, interfaces, typing and effects, highlighting recent achievements as well as open challenges.
Biography
Éric Tanter is an Associate Professor in the Computer Science Department of the University of Chile, where he co-leads the PLEIAD laboratory. He received the PhD degree in computer science from both the University of Nantes and the University of Chile (2004). His research interests include programming languages and tool support for modular and adaptable software.Placeholder for trashed attachments
-- PeterThoeny - 28 Jun 2002Home Day 1 Editor Day 2? Day 3 Day 4 Static Analysis Day 5 Day 6 Day 7 Code Generation Day 8 Day 9 Day 10
Anatomy of a Test Suite
The initial project contains an example test suitetests/example.spt:
module example language MiniJava start symbol Start test constant [[42]] parse succeeds test incomplete constant [[4]] parse failsThe first three lines specify the name of the test suite, the language under test, and the start symbol used for a test. The next two lines specify a positive and a negative test case (for now, you can ignore the third test case). Each test case consists of a name, a code fragment in double square brackets, and a condition which determines what kind of test should be performed (parsing) and what the expected outcome is (success or failure). You can run the test suite from the Transform menu. This will open the Spoofax Test Runner View which provides you information about failing and succeeding test cases in a test suite. You can also get instant feedback while editing a test suite.
MiniJava Syntax Definition
In order to write your own test cases, you need to understand MiniJava's syntax. Here is the ultimate MiniJava syntax definition from the book "Modern Compiler Implementation in Java", 2nd edition. The MiniJava syntax definition from the book says nothing about reserved words. But it states that the meaning of a MiniJava program is given by the meaning as a Java program. Therefore, you should treat all reserved words in Java as reserved in MiniJava as well and provide test cases which address this issue.Test Cases
You can now start writing your own test cases.Lexical and Context-free Syntax
Start with the lexical syntax and think about valid and invalid identifiers. Try to focus on corner cases like- identifiers made of a single character,
- mixings of letters and digits (Which kinds of mixing are allowed? Which are not?),
- underscores in identifiers.
tests/ directory.
Program, MainClass, ClassDecl, VarDecl, MethodDecl, Type, Statement, Exp, ID and INT. For grading, it is required to comply with these sort names literally.
|
Abstract Syntax
Next, you should focus on abstract syntax trees. Come up with positive test cases which specify the expected ASTs.
test integer constant [[42]] parse to SomeFancyConstructor("42")
Think about good constructor names.
Your ASTs should meet the following requirements:
- Similar things are represented in a similar way, e.g.
- classes without a parent are represented similarly to classes with a parent,
- variable references on the left-hand side and on the right-hand side of assignments should be represented the same way,
- different things are represented differently, e.g.
- field declarations are distinguishable from variable declarations,
- identifiers in declarations are distinguishable from identifiers in references,
- constructor names focus on the semantic of a construct, not on the syntax, e.g.
- binary expressions are named after the operation, not after the operator symbol.
FormalList and ExpList as flat lists.
|
Disambiguation
Next, you need to focus on disambiguation. Come up with positive test cases which specify the correct ASTs for nested expressions. As an alternative, you can also specify two fragments in concrete syntax, which should result in the same AST:test left associative addition [[21 + 14 + 14]] parse to [[(21 + 14) + 14]]Here you can find a table listing the associativity and priorities of operators in Java.
|
|
Layout
Finally, you can focus on layout. Think about places where whitespace is not optional but mandatory and define corresponding positive and negative test cases. Finish with test cases for single-line comments, standard block comments, and nested block comments.| %GS% Challenge: Single-line comments cannot only end with a newline character, but also at the end of file. |
8 PhpFront
6 AndreaScavuzzo
6 WebIndex
6 WebChanges
5 WebHome
4 WebTopicList
4 TrashAttachment
3 RetireYACCGrammar
3 GpceWorkshops
2 Lochtml
37 WebHome
32 TWikiGuestLeftBar0
25 WebChanges
19 PhpFront
16 WebIndex
14 WebLeftBar
13 AndreaScavuzzo
11 WebTopicList
11 Lochtml
11 RetireYACCGrammar
27 WebChanges
23 WebIndex
21 WebStatistics
19 PhpFront
14 AndreaScavuzzo
14 WebLeftBar
14 TrashAttachment
11 WebTopicList
11 WebPreferences
10 WebNotify
21 WebHome
20 WebChanges
20 TrashAttachment
17 PhpFront
16 WebIndex
13 AndreaScavuzzo
13 RetireYACCGrammar
13 WebPreferences
13 WebLeftBar
11 WebTopicList
37 WebStatistics
22 WebChanges
20 PhpFront
19 WebNotify
17 AndreaScavuzzo
17 WebIndex
15 RetireYACCGrammar
15 TrashAttachment
14 WebPreferences
14 WebLeftBar
50 JerryJuarez
29 WebHome
19 WebIndex
19 TrashAttachment
18 WebChanges
17 AndreaScavuzzo
17 PhpFront
16 WebNotify
16 WebLeftBar
13 RetireYACCGrammar
64 TrashAttachment
56 WebHome
47 RetireYACCGrammar
43 WebChanges
40 PhpFront
38 WebIndex
31 AndreaScavuzzo
30 WebLeftBar
24 WebTopicList
24 WebPreferences
93 TrashAttachment
92 WebHome
68 RetireYACCGrammar
60 WebTopicList
59 PhpFront
51 WebPreferences
50 WebIndex
47 WebNotify
47 WebChanges
42 WebLeftBar
75 WebHome
58 TrashAttachment
48 RetireYACCGrammar
47 PhpFront
43 WebIndex
35 WebPreferences
33 WebTopicList
33 WebChanges
28 WebLeftBar
27 WebNotify
62 TrashAttachment
51 WebHome
46 PhpFront
40 WebPreferences
38 WebChanges
34 WebIndex
34 RetireYACCGrammar
32 WebLeftBar
30 WebTopicList
28 WebNotify
52 WebHome
52 WebChanges
41 PhpFront
38 TrashAttachment
30 WebLeftBar
26 WebIndex
26 RetireYACCGrammar
24 WebPreferences
23 WebTopicList
21 WebNotify
45 WebChanges
44 WebIndex
42 TrashAttachment
35 WebHome
33 RetireYACCGrammar
29 PhpFront
26 WebLeftBar
22 WebTopicList
18 WebSearch
17 WebNotify
55 TrashAttachment
51 WebIndex
43 PhpFront
41 WebPreferences
40 WebChanges
38 WebHome
34 WebLeftBar
31 RetireYACCGrammar
28 AndreaScavuzzo
26 WebTopicList
57 WebHome
57 WebIndex
57 WebChanges
56 TrashAttachment
48 WebNotify
42 WebPreferences
40 PhpFront
31 WebTopicList
27 RetireYACCGrammar
27 WebLeftBar
43 WebChanges
41 WebHome
38 PhpFront
35 WebIndex
35 TrashAttachment
33 WebNotify
29 RetireYACCGrammar
29 WebLeftBar
25 WebTopicList
22 WebPreferences
73 WebHome
60 WebChanges
50 WebIndex
47 TrashAttachment
44 WebNotify
35 WebTopicList
34 WebPreferences
32 WebLeftBar
27 PhpFront
22 WebSearch
62 WebHome
49 TrashAttachment
38 WebIndex
37 WebNotify
35 WebChanges
33 WebPreferences
22 WebTopicList
18 WebLeftBar
12 WebSearch
11 WebSearchAdvanced
69 WebStatistics
34 TrashAttachment
33 WebChanges
24 WebNotify
23 WebSearch
22 WebIndex
18 WebPreferences
15 WebTopicList
9 WebLeftBar
8 PhpFront
- Do not edit this topic, it is updated automatically. (You can also force an update)
- TWikiDocumentation tells you how to enable the automatic updates of the statistics.
- Suggestion: You could archive this topic once a year and delete the previous year's statistics from the table.
- ABICompatibilityThroughACustomizableLanguage
- AComponentbasedRuntimeEvolutionInfrastructureForResourceConstrainedEmbeddedSystems
- AbstractDeltaModeling
- AddingGenericityToAPluginFramework
- AndreaScavuzzo
- ApplicationsOfDynamicCodeEvolutionForJavaInGUIDevelopmentAndDynamicAspectOrientedProgramming
- AutomaticAndEfficientSimulationOfOperationContracts
- AutomaticVariationPointIdentificationInFunctionBlockBasedModels
- BlW
- CCTrashWebHome
- CodeClonesInFeatureOrientedSoftwareProductLines
- CompositionOfDynamicAnalysisAspects
- Day1
- Day3
- Day4
- Day5
- Day5-old
- Day6
- Day7
- DomainSpecificLanguageIntegrationWithCompileTimeParserGeneratorLibrary
- EfficientExtractionAndAnalysisOfPreprocessorBasedVariability
- GpceTutorials
- GpceWorkshops
- HistoricalStatistics
- ImplicitInvocationMeetsSafeImplicitConcurrency
- IncrementalType-CheckingForType-ReflectiveMetaprograms
- IterativeTypeInferenceWithAttributeGrammars
- JEqualityGenGeneratingEqualityAndHashingMethods
- JerryJuarez
- LaTex
- LightweightModularStagingAPragmaticApproachToRuntimeCodeGenerationAndCompiledDSLs
- Lochtml
- MartinErwigInvitedTalk
- ModelBasedKinematicsGenerationForModularMechatronicToolkits
- ModularDomainSpecificLanguageComponentsInScala
- NewSandboxTopic
- ObjectOrientedQueriesOverSoftwareSystems
- PhpFront
- RetireYACCGrammar
- SlidesFolder
- TWikiGuestLeftBar0
- TanterInvitedTalk
- TrashAttachment
- TrashCCWebLeftBar
- TrashDay2
- WebChanges
- WebHome
- WebIndex
- WebLeftBar
- WebNotify
- WebPreferences
- WebSearch
- WebSearchAdvanced
- WebStatistics
- WebTopicList
Number of topics: 55